In this introductory post, I introduce what Machine Learning is in hopefully a widely accessible language. I aim to minimize as many buzzwords as possible though certain terminologies such as matrices, vectors, statistical models, parameters, etc. will come up. A basic understanding of what these terms mean is assumed.
What is Machine Learning?
According to computer scientist Arthur Samuel in 1959, Machine Learning is a subfield of Computer Science that gives “computers the ability to learn without being explicitly programmed.”
Let’s dissect this statement. Normally a computer program that you interact with everyday (e.g. web browser, Word Document editing program, Excel, iPhone apps, etc.) is written by a coder to respond to some input using arbitrary rules and logic defined by the said coder and perform whatever its indended functionalities are. Think: when a user taps on a button on an app, the coder must write logic for the app to respond to such input.
What about tasks that don’t have such straightforward logic such as classifying whether an image contains cats or not? For humans, this kind of task comes naturally but not so for computers. After all, an image is basically a matrix of 0s and 1s to a computer. Put yourself into a computer’s shoes, how can you recognize an arbitrary such matrix contains a cat in it or not? More generally, how can we write computer programs that achieve human-level performance in this kind of task?
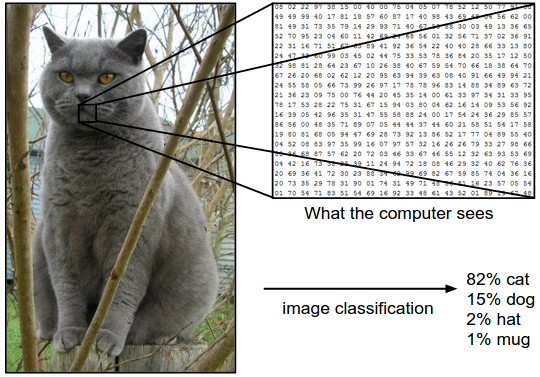
The answer, at least for now, lies in writing computer programs that make decisions relying on outputs from statistical models which extract insights/patterns from large quantities of data available. Machine Learning is the scientific study of these statistical models.
Going back to classifying cat images task, instead of manually defining rules (which is impossible anyway) about what a cat image should look like, you can build a Machine Learning (ML) model that has been trained on a large collection of cat and non-cat images that have been labeled. In ML literature, this large collection of image data is generally referred to as training data. You, as a programmer, only need to input this training data into your Machine Learning model, from which it can automatically learn model parameters using some training algorithm. Then for any unforeseen image (i.e. not in training data) fed into your model, based on model parameters learned during training, your model can predict whether the given image contains cats or not. Your computer program, utilizing such cat-classifying ML model which is trained on the prepared cat images data set, outputs the desired answer based on outputs of the model.
Major categories of ML
There is a wide variety of tasks that ML algorithms/models can solve.
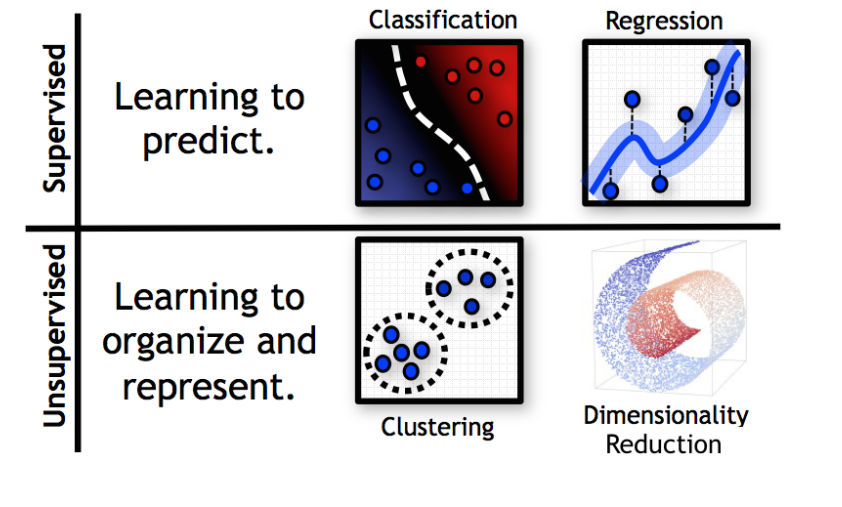
There are 4 main subtasks in Machine Learning, divided into 2 main categories (see Figure 1) which are supervised and unsupervised learning 1. The main difference between the two categories is that in supervised learning training data requires labelling, which is not the case in unsupervised learning.
Most of supervised learning tasks are of 2 types: classification and regression.
The cat image prediction example in the previous section is an example of classification: given training data and categorical labels, a classification model’s goal is to predict which category an unforeseen data case belongs to.
For regression tasks, target labels are continuous rather than categorical; predicting house prices given housing details is an example of a regression task.
Unsupervised learning tasks can be either clustering or dimensionality reduction tasks.
Clustering involves dividing the data set under consideration into meaningful groups, or clusters, where data belonging to the same group is more “similar” to each other than others. Examples of clustering include market segmentation and gene sequence analysis.
Dimensionality reduction task involves projecting data from original data space into a lower-dimensional subspace, while preserving certain desired properties. Often, dimensionality reduction can be used for visualizing complex data or as a preprocessing step for supervised learning tasks.
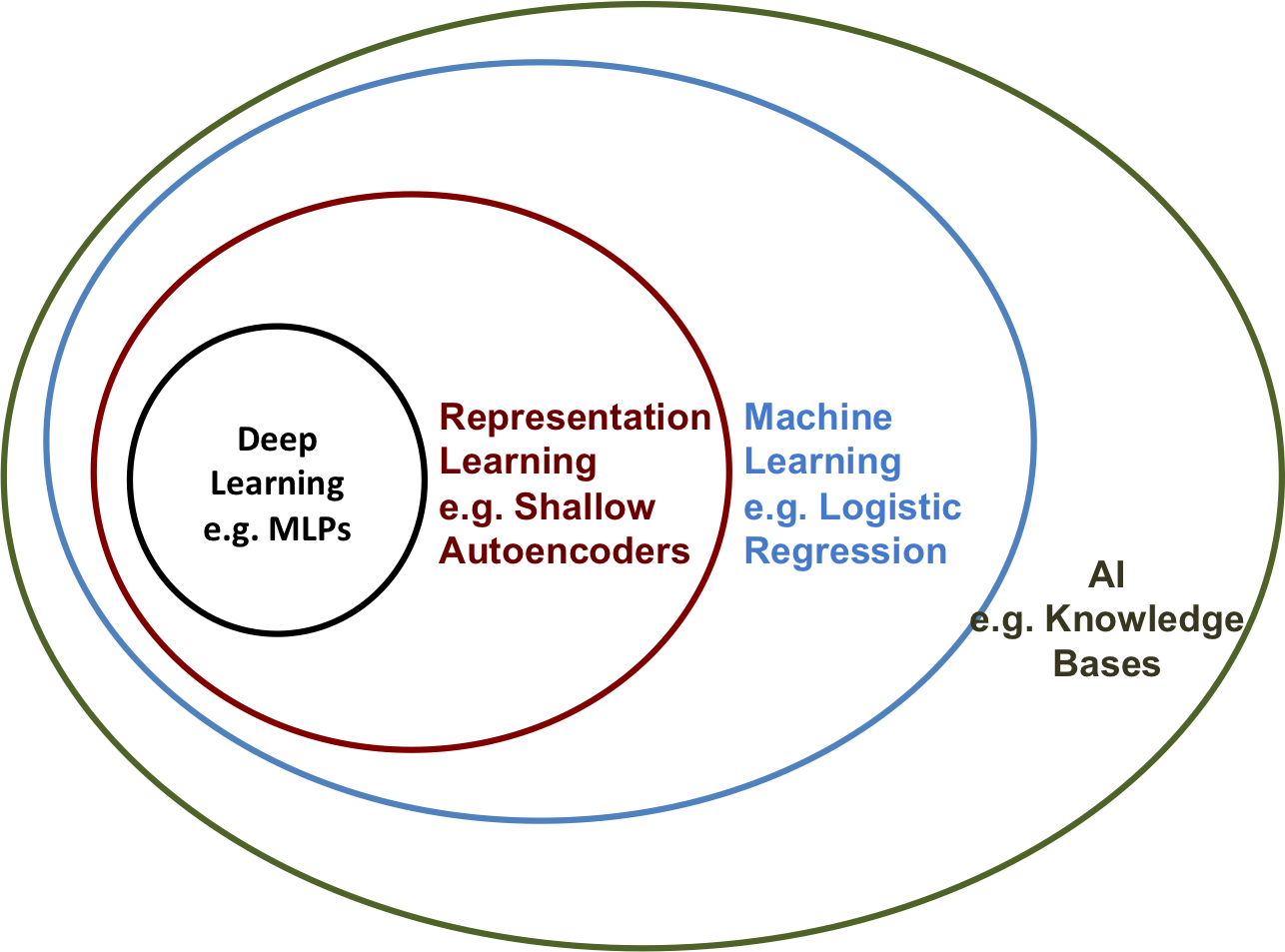
ML hierarchy within AI
Machine Learning is a subset of Artificial Intelligence, which has a more general definition: AI is the scientific study and development of computer systems that can perform tasks that normally require human intelligence. Machine Learning is only one way of making computers able to achieve human-level performance on such tasks. Its main distinguishing feature from other subfields of AI is its reliance on statistical models and vast amount of data.
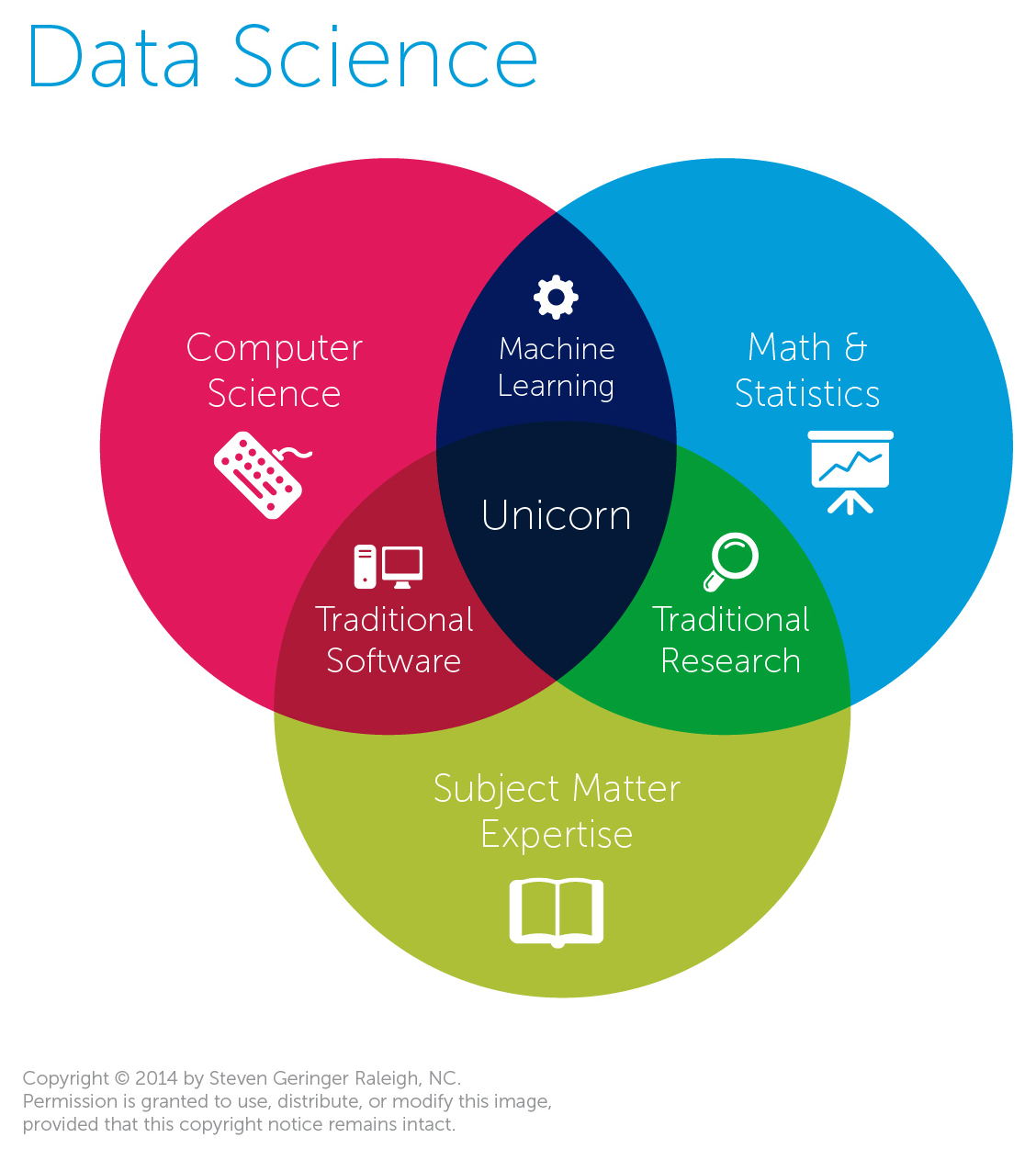
ML’s relationship with Data Science
While these two fields are closely related, many people seem to conflate these two together. I think a helpful distinction between these two fields can be made if one can understand the differences/overlap in responsibilities between practitioners of these two (i.e. an ML engineer/researcher and a data scientist).
For both of these roles, they need to know statistical modelling techniques both in theory (how they work) as well as practical considerations to make when applying them to real data. They both need to know how to preprocess, engineer features from the given data so that their models can effectively learn from it. Other common tasks include deciding appropriate evaluation metrics, fine tuning models using some optimization strategy.
For an ML engineer, they also need to make sure that the models that they developed to solve their particular problems are production-ready and maintainable. In other words, software engineering (beyond just knowing basic programming languages) is a must in their skillset.
A data scientist’s toolkit includes more than just using/developing statistical models. They also need to understand how to translate their insights from modeling the data into actionable business advice: this can be anything ranging from using communication skills, business sense to using data visualization techniques to convince key stakeholders about their recommendations. While programming experience can certainly help a data scientist succeed in their job, their primary skillset tends to heavily skew towards more statistics knowledge.
Another useful way of distinguishing between ML and DS is illustrated by this Venn diagram below.
How is ML/DS useful?
A simple Google search should yield plenty of articles on the impact of ML on modern society. Here’s a non-exhaustive list of ML applications:
- Spam email filtering
- Movie/Ads/Product recommendation
- Chatbots/Question and Answering systems
- Online fraud detection
- Virtual assistants (e.g. Siri, Alexa, Google Now)
- Medical Diagnosis
Resources
More elegant introductions to this topic have been around on the internet. Here are a few of those resources which this post owes much of its content from:
- There are other ML tasks such as reinforcement learning and semi-supervised learning, but these will not be discussed here. [return]